
Las pruebas de regresión son un eslabón clave en un flujo moderno de desarrollo DevOps, y cada vez se vuelven más necesarias en entornos IBM i (AS400 – iSeries). Básicamente, este tipo de pruebas asegura que cada cambio en el software no interfiera con las funcionalidades existentes, minimizando así el riesgo de efectos colaterales cuando los desarrollos llegan a producción.
La esencia de las pruebas de regresión es garantizar que lo que ya funciona, siga funcionando correctamente y no afecte en lo más mínimo la operación diaria de la empresa. Después de décadas de uso, el IBM i se ha convertido en un pilar fundamental para las operaciones de muchas organizaciones, desde bancos hasta compañías de retail, y cualquier error puede poner en riesgo no solo la operación del sistema, sino también la salud financiera de la empresa.
Por esto, las pruebas de regresión son una herramienta esencial para garantizar la estabilidad del sistema y reducir costos al minimizar los riesgos. Imagina el tiempo y los recursos que se pueden ahorrar evitando que problemas lleguen a producción y sean detectados por el usuario final.
En este artículo, exploraremos en profundidad qué son las pruebas de regresión, para qué son útiles, los retos en entorno IBM i, los beneficios de su aplicación y las herramientas que facilitan este proceso, como ARCAD Verifier. Al finalizar, tendrás una visión clara de por qué integrar las pruebas de regresión en tu flujo de desarrollo no solo mejora la calidad del software, sino que también protege la operación del negocio.
Como su nombre indica, las pruebas de regresión consisten en “regresar” a probar funciones que ya han sido probadas previamente y que actualmente funcionan sin problemas. Su objetivo es verificar que cualquier modificación o desarrollo nuevo no afecte funciones relacionadas en las aplicaciones o sistemas involucrados, ya sea de manera directa o indirecta. Detectar estos errores de forma temprana disminuye significativamente los costos y evita que problemas pequeños se conviertan en incidentes graves en producción.
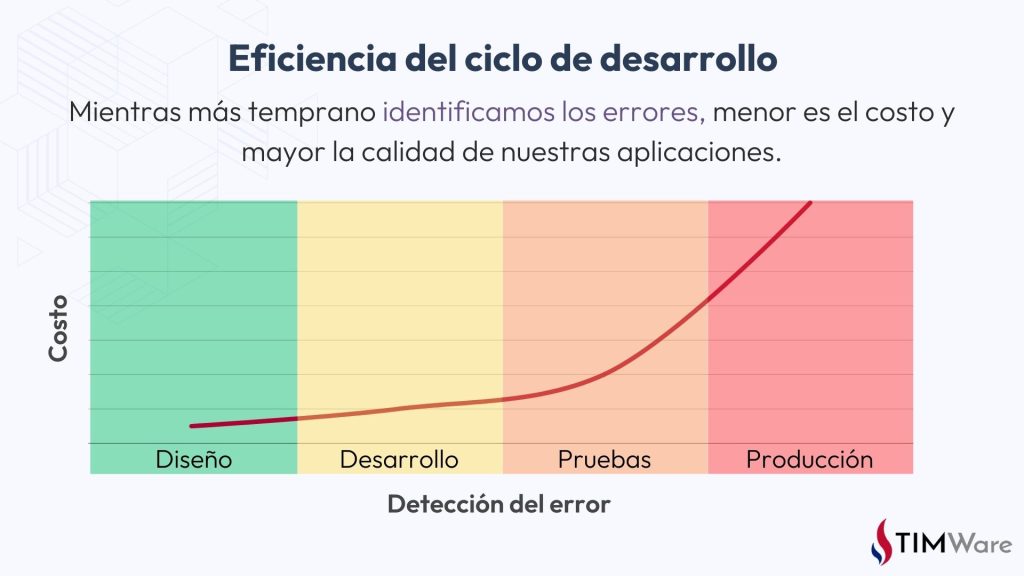
Siempre que hacemos cambios en una aplicación, es fundamental probar si el cambio funciona como debería y si no genera problemas en la propia aplicación. Sin embargo, también existe la posibilidad de que ese cambio afecte indirectamente otras áreas del código o del sistema que no están directamente relacionadas con él.
Te podría interesar leer: Auditoría de código en IBM i: Detección temprana de errores con Shift Left
Cuando se carece de documentación o conocimiento preciso sobre las aplicaciones que se modifican —una situación común en entornos IBM i—, es fácil perder de vista interdependencias entre aplicaciones. Esto puede provocar que, de forma inesperada, una aplicación aparentemente independiente de la que fue modificada sufra problemas o errores al llevar el cambio a producción. Liberar cambios a producción con errores puede ser catastrófico para el negocio y aún más complicado de solucionar si no se cuenta con herramientas o formas de hacer rollbacks eficientes.
Las pruebas de regresión están diseñadas para identificar estos posibles efectos colaterales antes de que los desarrollos lleguen a producción, asegurando la estabilidad del sistema y la continuidad operativa. La forma de llevarlas a cabo es ejecutando diferentes escenarios de casos de uso habituales en la aplicación y en otras áreas del sistema, como explicaremos a continuación.
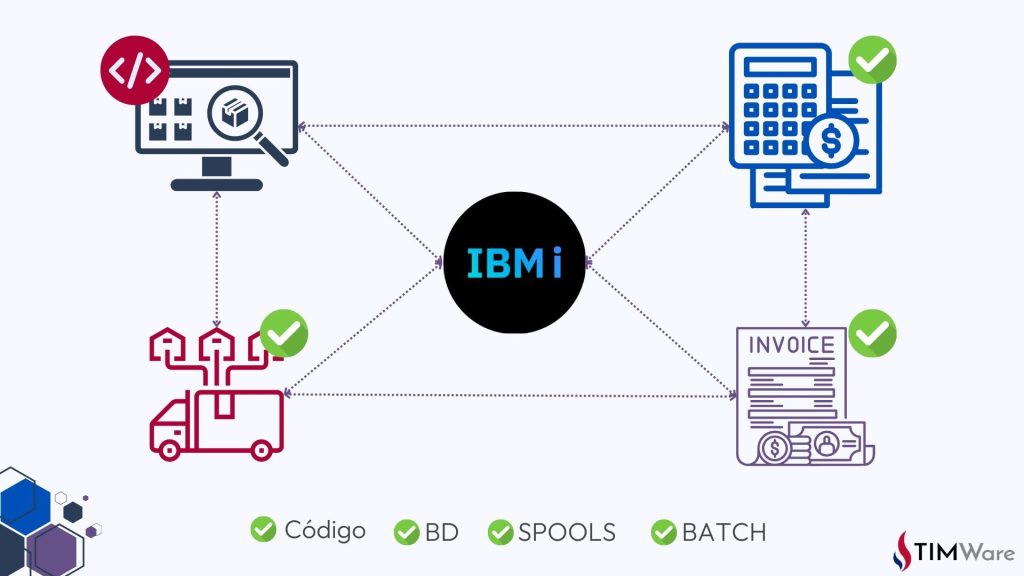
Imaginemos que en una empresa se utiliza un sistema en IBM i para gestionar inventarios y ventas. Este sistema incluye funcionalidades clave, como el procesamiento de órdenes, la actualización de inventarios y la generación de reportes de ventas. Supongamos que el equipo de desarrollo ha añadido una nueva funcionalidad que aplica descuentos especiales a ciertos productos. Antes de llevar este cambio a producción, es fundamental realizar una prueba de regresión para asegurarse de que esta nueva función no afecte otras áreas del sistema.
Paso 1: Identificación de áreas críticas para la prueba
El primer paso es identificar las áreas críticas del sistema que podrían verse afectadas indirectamente por la nueva funcionalidad de descuentos. En este ejemplo, los módulos de procesamiento de órdenes, actualización de inventarios y generación de reportes de ventas son puntos clave que deben probarse. Cualquier fallo en estas áreas podría causar interrupciones importantes en la operación diaria.
Paso 2: Configuración de los casos de prueba
Luego, el equipo establece casos de prueba para cada una de estas funcionalidades. Estos casos se configuran para capturar cómo se comportan actualmente estas funciones, sirviendo como un punto de comparación. La idea es tener un registro del funcionamiento esperado de cada proceso antes de aplicar el cambio.
Paso 3: Ejecución de la prueba de regresión
Una vez que se han configurado los casos de prueba, se ejecutan después de aplicar la actualización de descuentos. Este proceso implica comparar los resultados de la nueva versión del sistema con los resultados registrados en la versión anterior, verificando que:
Paso 4: Análisis de resultados y ajustes
Si las pruebas detectan alguna diferencia o error, como un problema en el cálculo del inventario después de aplicar el descuento, el equipo puede investigar y corregir el problema antes de liberar el cambio a producción. Esta revisión final asegura que cualquier efecto colateral o error oculto sea identificado y resuelto sin impactar a los usuarios finales.
Este proceso muestra cómo una prueba de regresión ayuda a proteger la estabilidad operativa y a evitar problemas en producción. Al probar que las funciones existentes no se ven afectadas por nuevas implementaciones, la empresa puede llevar a cabo mejoras continuas en su sistema IBM i sin comprometer la calidad del software ni la operación del negocio.
En entornos IBM i, las pruebas de regresión presentan algunos retos y particularidades que no se encuentran en la misma medida en ambientes open source. Aquí te compartimos los principales desafíos y diferencias:
El entorno IBM i es conocido por su robustez, especialmente en sistemas que operan aplicaciones legacy desarrolladas en lenguajes como RPG y COBOL. Estas aplicaciones suelen ser monolíticas y están diseñadas sobre la base de datos DB2, lo que crea una arquitectura centralizada muy distinta a los sistemas modulares que se encuentran en entornos open source.
En IBM i, un cambio en el código puede generar efectos colaterales en otras partes de la aplicación, lo cual hace que las pruebas de regresión sean aún más necesarias para asegurar que el sistema funcione de manera estable en cada actualización.
La mayoría de las herramientas de prueba automatizadas están orientadas a entornos open source y lenguajes modernos, lo que no siempre resulta compatible con IBM i. Esto se debe a que IBM i requiere herramientas que comprendan su interfaz (5250) y las estructuras de DB2 específicas del sistema.
En entornos open source, los desarrolladores cuentan con una amplia gama de herramientas personalizables y bien documentadas. Sin embargo, en IBM i, las opciones son más limitadas y suelen depender de herramientas comerciales, como ARCAD Verifier, que pueden realizar pruebas de regresión sin scripting y detectar cambios específicos de IBM i con precisión.
A medida que las empresas buscan integrar prácticas DevOps en IBM i, surge la necesidad de incorporar las pruebas de regresión en un pipeline de CI/CD. Sin embargo, IBM i puede ser difícil de integrar con herramientas de automatización de pruebas estándar, como Selenium o Jenkins, debido a su estructura y tecnologías propietarias.
Esto contrasta con los entornos open source, donde los pipelines se configuran fácilmente para ejecutar pruebas de regresión de manera automática con cada commit. En IBM i, se requieren soluciones específicas como ARCAD Verifier, que se pueden integrar en el pipeline y ejecutar las pruebas de regresión como parte de un flujo de trabajo DevOps.
IBM i utiliza una estructura de datos única basada en DB2, lo que exige un enfoque especializado para la creación y manipulación de datos de prueba. A diferencia de las bases de datos SQL y NoSQL comunes en open source, donde los datos de prueba se pueden crear y versionar con mayor flexibilidad, los datos en IBM i requieren un entorno de prueba que respete su estructura.
En este caso, herramientas como ARCAD Verifier permiten el manejo automático de datos de prueba, lo que resulta clave para optimizar el proceso y asegurar la integridad del sistema en cada ciclo de prueba.
Automatizar pruebas en IBM i generalmente implica inversiones en herramientas especializadas y capacitación de los equipos, dado que las habilidades requeridas son específicas y menos comunes en el mercado. En open source, la disponibilidad de herramientas gratuitas y el apoyo de una comunidad activa facilitan la adopción de frameworks sin costos iniciales elevados.
Sin embargo, en IBM i, la dependencia de soluciones comerciales conlleva una curva de aprendizaje y costos adicionales, lo cual hace que el uso de herramientas específicas sea casi imprescindible.
Las pruebas de regresión en IBM i deben tener en cuenta la seguridad y el cumplimiento normativo, ya que suelen manejar datos críticos en sectores altamente regulados como finanzas o manufactura. Las pruebas de regresión deben generar registros detallados que garanticen el cumplimiento de estándares y permitan auditorías.
Herramientas como ARCAD Verifier resultan útiles en IBM i, ya que generan informes detallados y aseguran que los cambios en las aplicaciones no introduzcan vulnerabilidades en el sistema.
Para las empresas que operan en entornos IBM i, la automatización de las pruebas de regresión es una necesidad para evitar que el proceso de desarrollo se vuelva ineficiente y costoso. Aquí es donde ARCAD Verifier se convierte en una herramienta esencial, ya que simplifica y optimiza la ejecución de pruebas de regresión de una manera que los métodos manuales no pueden alcanzar.
ARCAD Verifier permite automatizar el proceso completo de pruebas de regresión en IBM i, haciendo que sea fácil para el equipo de desarrollo configurar y ejecutar pruebas sin necesidad de scripting ni intervenciones manuales complejas. A través de una interfaz intuitiva, los usuarios pueden grabar casos de prueba clave que reflejan el comportamiento esperado de la aplicación en IBM i, capturando tanto las interacciones en la interfaz de usuario como los cambios en la base de datos DB2 y en los archivos spool.
Características clave de ARCAD Verifier:
Las pruebas de regresión son un paso esencial en el proceso de desarrollo de software, y llevarlas a cabo de manera continua es clave para cumplir con las prácticas modernas de CI/CD. Sin embargo, estas pruebas pueden convertirse en un verdadero cuello de botella cuando se realizan manualmente, ralentizando el desarrollo y limitando la frecuencia de los lanzamientos. Esto afecta la capacidad de las empresas para responder a las demandas y expectativas de un mercado en constante cambio, resultando en desarrollos estables y seguros pero a un ritmo lento y poco frecuente.
La automatización de las pruebas de regresión es esencial para un proceso de desarrollo fluido y eficiente. ARCAD Verifier y otras herramientas de automatización permiten que las pruebas se integren naturalmente en el flujo de trabajo, eliminando retrasos y asegurando que cada cambio en el sistema mantenga la estabilidad de la aplicación. Con una solución como ARCAD Verifier, las empresas en IBM i pueden garantizar que sus aplicaciones sean seguras, estables y capaces de adaptarse rápidamente a nuevas necesidades del mercado.